 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-LiveTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Dec 31, 2025Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-LiveTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-LiveTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
Assigning personality/identity to a chatting machine for coherent conversation generation
Jun 21, 2017
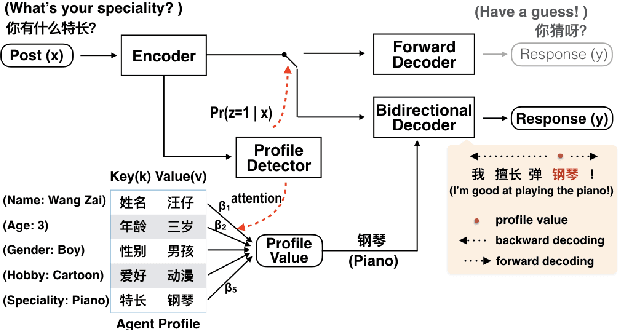
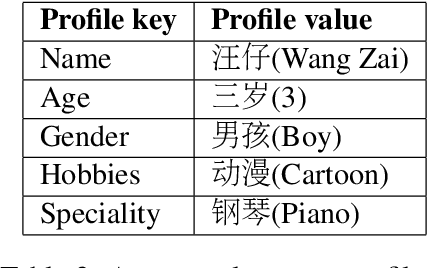
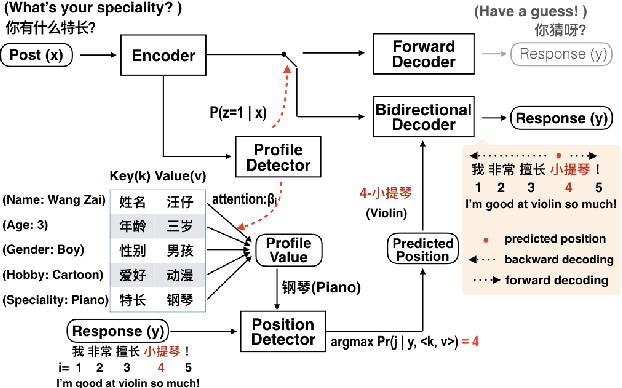
Endowing a chatbot with personality or an identity is quite challenging but critical to deliver more realistic and natural conversations. In this paper, we address the issue of generating responses that are coherent to a pre-specified agent profile. We design a model consisting of three modules: a profile detector to decide whether a post should be responded using the profile and which key should be addressed, a bidirectional decoder to generate responses forward and backward starting from a selected profile value, and a position detector that predicts a word position from which decoding should start given a selected profile value. We show that general conversation data from social media can be used to generate profile-coherent responses. Manual and automatic evaluation shows that our model can deliver more coherent, natural, and diversified responses.
Linguistically Regularized LSTMs for Sentiment Classification
Apr 25, 2017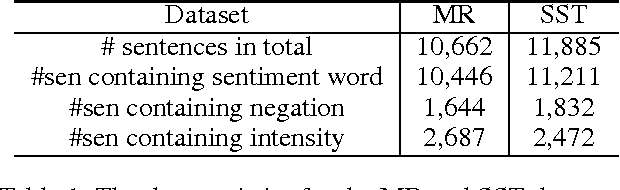
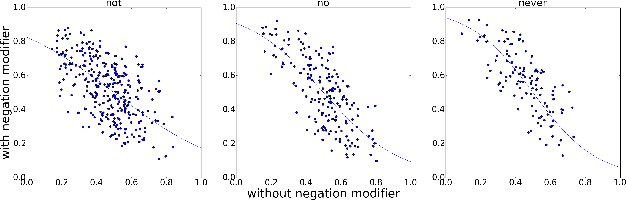
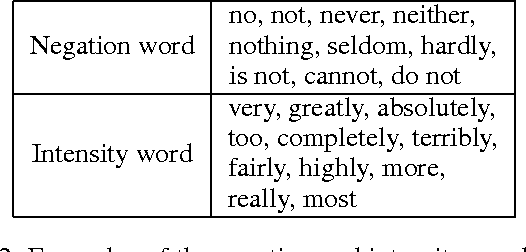
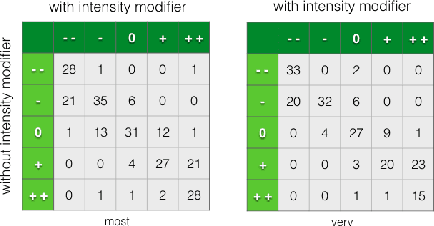
Sentiment understanding has been a long-term goal of AI in the past decades. This paper deals with sentence-level sentiment classification. Though a variety of neural network models have been proposed very recently, however, previous models either depend on expensive phrase-level annotation, whose performance drops substantially when trained with only sentence-level annotation; or do not fully employ linguistic resources (e.g., sentiment lexicons, negation words, intensity words), thus not being able to produce linguistically coherent representations. In this paper, we propose simple models trained with sentence-level annotation, but also attempt to generating linguistically coherent representations by employing regularizers that model the linguistic role of sentiment lexicons, negation words, and intensity words. Results show that our models are effective to capture the sentiment shifting effect of sentiment, negation, and intensity words, while still obtain competitive results without sacrificing the models' simplicity.